



🌟 Introduction
It's been 6 months since I started my journey in the LFX mentorship program, and my project revolves around building a comprehensive performance analytics solution for Hyperledger Fabric using Hyperledger Caliper.
Firstly, I would like to thank and express my gratitude to my mentors, Attila Klenik and Haris Javaid, for their support throughout this period. At first, the project and new technologies were overwhelming but with their guidance, it became easier over time.
You can check out our project's code here: Repository Link
🖥️ Terminology Overview
For those unfamiliar with the terminology, let me give a quick introduction to the basics:
Hyperledger Fabric: An open-source blockchain platform.
Caliper: A blockchain benchmark framework to measure performance
ELK + Logspout: The ELK stack includes Elasticsearch, Logstash, and Kibana.
➡️ Project Initialization
Before initiating the project, I collected logs from a variety of sources, including state-based chaincode and private data chaincode, encompassing both INFO and DEBUG levels of information. Additionally, during this phase, I learned a lot about consensus mechanisms within the Fabric framework and Open Telemetry.
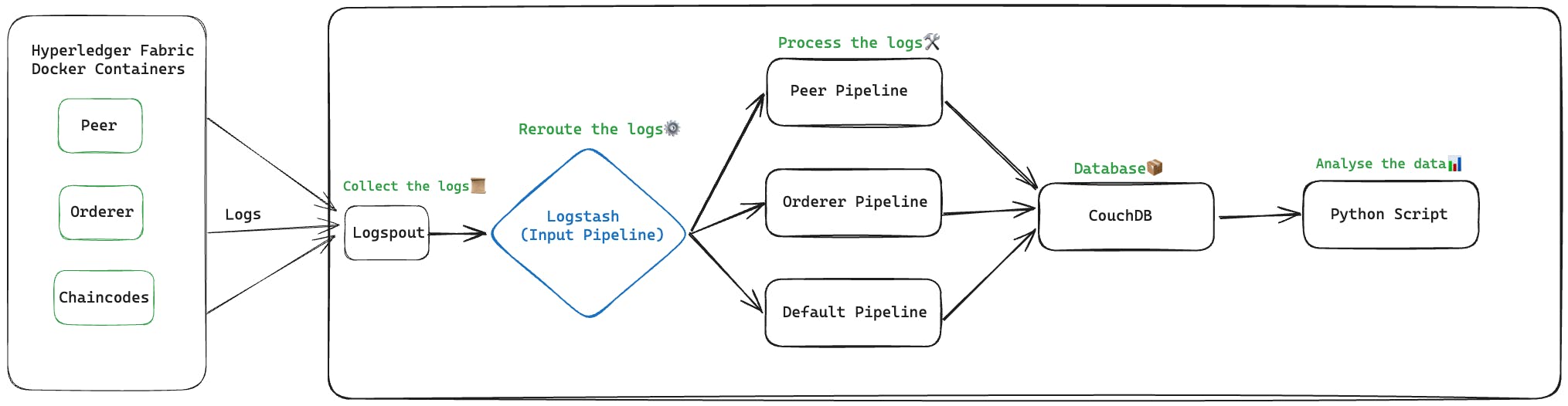
Now, we are creating an external service that is responsible for collecting logs from Docker repositories, then processing and storing them in a database. This time we chose to use the ELK stack, which is easily implemented in the Docker Compose environment.
📜 ELK + Logspout Stack
Here's how we use the ELK + Logspout stack, breaking down the role of each component:
Logspout: A simple but essential service that collects logs from all working Docker containers and returns them to Logstash instances for further processing.
Elasticsearch: Currently serving as our temporary log storage solution, but in the future, we plan to switch to a lightweight NoSQL database.
Logstash: The central part of our stack, where logs are received from Logspout and processed efficiently. In Logstash, we extract useful information and convert logs into structured systems, ensuring they are ready for analysis.
Kibana - Our go-to tool for visualizing carefully applied data.
I remember spending several hours troubleshooting a connectivity issue between Logstash and Logspout during the ELK setup, only to eventually realize that I had mistakenly mounted the configuration to the wrong location in Docker😅
Also, I really enjoyed working with Logstash's config format. It's really cool!!
🚀 Multi-pipeline Configuration in Logstash
Now, let’s dive deeper into our implementation of multi-pipeline configuration in Logstash:
1. Input Pipeline
Responsibility: This pipeline serves as the entry point for all incoming logs.
Processing: In this phase, we perform the initial processing tasks, including extracting the necessary information from the Docker message.
Transformaing: The selected data is organized in the top-level format of the "container_info" object, which includes information such as version, container ID, image name, service, type, and so on.
"container_info": { "version": "latest", "id": "074c8fe4e8568fc8db0ccbb4dd9e6a985def6649ff480b7cebece0336edc4770", "image_name": "hyperledger/fabric-peer:latest", "service": "/peer0.org1.example.com", "type": "peer" },
2. Order Pipeline
Purpose: Our intention in this pipeline is to extract specific information from two types of log messages:
Logs generated by creating a block.
Logs generated while writing a block.
3. Peer Pipeline
Objective: Our objective in the peer pipeline is to extract sensitive information such as execution time, state authentication time, and commit time from 4 types of log messages:
Logs associated with validated blocks.
Logs of committed blocks.
Logs associated with received blocks.
Possibly gateway logs
4. Default Pipeline
- Processing the Rest: Any logs that do not match the classes of the peer or orderer are forwarded to the default pipeline for further processing and handling.
🐍 Python Script
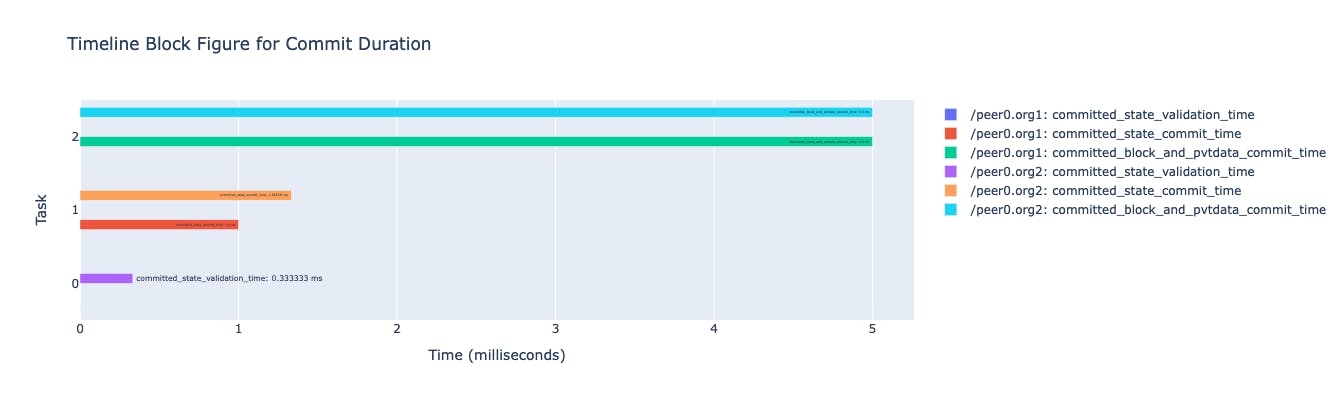
Now, we have created a Python script, which will retrieve the pre-processed data from the CouchDB database.
Then, It will do processing on it, for example calculating the extra performance related fields like state_validation_start, state_validation_end from pre-existing fields.
Further, we can visualize the processed data using various diagrams. For example:
💙 Closing with Gratitude
This was our journey so far. Thank you for taking the time to read🙏
We value your insights and suggestions.
Please feel free to share your feedback with us and stay tuned for the exciting developments and insights that lie ahead ✨